我们在日常业务开发以及架构工具、框架时经常会遇到图片处理、视频处理等等情况,那么js代码到底处理的是什么呢?
一、几种常用数据存储单位的转换
在计算机内部,所有信息最终都是一个二进制值。
| 单位 | 可选值 | 意义 |
|---|---|---|
| Bit(位) | 0 1 | 电脑记忆体中最小的单位,在二进制电脑系统中,每一bit可以代表0或1的数位讯号 |
| Byte(字节) | 01010101 | 一个byte由8 bits组成,可代表一个字元(A~Z)、数字(0~9)、或符号(,.?!@#$%^&*/),是记忆体储存资料的基本单位 |
| ASCII | 0~2^8-1 | 上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。ASCII码一共规定了128个字符的编码,如空格是32(00100000)。这128个符号,只占用了一个字节的后面7位,前面统一规定为0 |
| Unicode(万国码) | 0x0000~0x10FFFF | 将世界上所有的符号都纳入其中,现在可以容纳100多万个符号,每个符号的编码都不一样:u0639表示阿拉伯字母Ain,u0041表示英语的大写字母A,u4E25表示汉字严。具体符号对应可查阅https://home.unicode.org/ |
| UTF-8 单字节 | 0x7F->0xxxxxxx (兼容ASCII) | UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8 是 Unicode 的实现方式之一。 |
| UTF-8 双字节 | 0x80~0x7FF->110xxxxx 10xxxxxx | x表示0或1 |
| UTF-8 三字节 | 0x800~0xFFFF-> 1110xxxx 10xxxxxx 10xxxxxx | x表示0或1 |
| UTF-8 四字节 | 0x10000~0x1FFFFF-> 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | x表示0或1 |
还有UTF-16、UTF-32等等。
1、UTF-8的产生是因为它之前的两个码存在一些存储和区分的问题:
-
由于ASCII码和unicode码都是存储的二进制,那么如何才能区分二者呢,计算机怎么知道三个字节代表一个符号还是三个符号?
-
如果unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前肯定有2~3个字节都是0,对于存储来说是极大的浪费,文本大小也会大出2、3倍。
2、单位换算:
1B = 1 byte = 8 bits
1KB = 1024 bytes = 2^10 bytes
1MB = 1024KB = 2^20 bytes
1GB = 1024MB = 2^30 bytes
3、UTF-8的编码规则
UTF-8是一种变长的编码方式,他可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
特点如下:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码,因此对于英文字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设置为1,第n+1位设置为0,后面字节的前两位一律设置为10,剩下的没有体积的二进制位,全部为这个符号的unicode码。
4、一个简单的各个编码之间的转换例子:
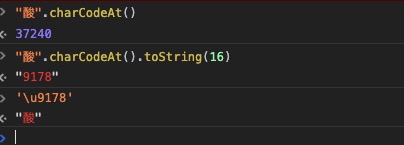
- 37240代表十进制的”酸”的ASCII码。charCodeAt返回 0~65535 之间的整数。
- 9178代表十六进制的”酸”的ASCII码。
- 十六进制的”酸”的ASCII码 + \u 又转回了文字。
二、ArrayBuffer
ArrayBuffer对象、TypedArray对象、DataView对象是JavaScript操作二进制数据的一个接口.
ArrayBuffer是用来表示通用的,固定长度的原始二进制数据缓冲区,不能直接对其进行操作,要通过类型数组对象或DataView来操作,它们把缓冲区的数据表示成特定的格式,并通过这些格式来读写缓冲区的内容。
1 | |
TypedArray支持9种数据格式的视图: Unit8Array(无符号8位整数)数组视图、Int16Array(16位整数)数组视图、Float32Array(32位浮点数)数组视图等。
DataView可以自定义格式和字节序。
参考文档: bit/byte/ascii/unicode