React进阶。
1、Fiber
1)什么是Fiber
FIber在react代码中代表一种数据结构,它表示react框架中渲染的每一个节点(比如自定义一个组件,在被调用时,会被转化成一个fiber节点,)。
由于渲染一个 React app,其实是在调用一个函数,函数本身会调用其它函数,形成调用栈,递归调用导致的调用栈我们本身无法控制, 只能一次执行完成。而 Fiber 就是为了解决这个痛点,可以去按需要打断调用栈,手动控制 stack frame——就这点来说,Fiber 可以理解为 virtual stack frame。
旧版 React通过递归的方式进行渲染,使用的是 JS 引擎自身的函数调用栈,它会一直执行到栈空为止。而Fiber实现了自己的组件调用栈,它以链表的形式遍历组件树,可以灵活的暂停、继续和丢弃执行的任务。实现方式是使用了浏览器的requestIdleCallback这一 API。
2)为什么要用Fiber架构,它的优点
是一种解决方案,为了解决在高频词的计算和渲染的情况下产生的卡顿和延迟渲染的问题(掉帧)。 在React执行中,老版本的最耗时的就是diff算法。原来的dom树是深度递归遍历,它只能不断递归遍历,直到stack调用栈为空。(不能随意中断和恢复)
原来的遍历代码:
1 | |
3)Fiber tree是如何遍历的
Fiber实现了自己的组件调用栈,它以链表的形式遍历组件树,可以灵活的暂停、继续和丢弃执行的任务。 Fiber遍历算法:
1 | |
Fiber依靠这个遍历算法做dom diff比较和更新。是整个fiber架构的核心。 遍历操作一直被执行在eventloop机制当中,从而实现了整个的fiber架构。
4)Fiber架构的特点
- 1)将对虚拟节点的遍历方式从递归遍历改成循环遍历;
- 2)可以在某个时刻暂停和恢复diff过程;
- 3)双缓存策略:current fiber tree和workInProgress fiber tree。两棵树永远在交替的变换更新页面。
双缓存策略优点:16版本之前是没有这个策略的,每次页面有更新都要重新构建一个dom树,有这个操作之后节省了大量构建虚拟dom的时间,性能大幅度提升。
5)Fiber是如何实现执行过程可以中断,执行完高优先级任务再回来重新执行
- 1、调度器:先讲requestIdleCallback方法,是什么、解决了什么问题。
1)调度器需要告诉diff流程是否应该暂停,这里需要实现上面的shouldYeild方法;
2)diff流程应该告诉调度器是否已经执行完毕,我们在diff流程被中断的时候同时传输当前状态给调度器;
3)调度器需要在合适的时候继续执行diff流程。
requestIdleCallback是js提供的API,用来在浏览器空闲时期依次调用函数。它的执行机制非常类似于setTimeout。setTimeout的执行原理:在 Chrome 中除了正常使用的消息队列之外,还有另外一个消息队列,这个队列中维护了需要延迟执行的任务列表,包括了定时器和 Chromium 内部一些需要延迟执行的任务。所以当通过 JavaScript 创建一个定时器时,渲染进程会将该定时器的回调任务添加到延迟队列中(不按顺序,按延迟时间遍历,哪个快要到执行时间就把哪个拿出来执行)。主线程的eventloop会定时查看延迟队列中是否有任务要到时间执行,如果没有继续循环,如果有,将要执行的任务放入消息队列等待执行。(scheduler调度就是模拟的requestIdleCallback)
-
扩充一下浏览器主线程的执行机制:主线程、事件循环、消息队列和其他现成的具体执行流程。
-
扩充一下微任务。每个宏任务都关联了一个微任务队列,存放了一些微任务。当前宏任务执行完,就会去对应的微任务队列中读取是否有要执行的微任务,如果有,全部拿到主线程执行掉,如果没有,执行下一个宏任务。
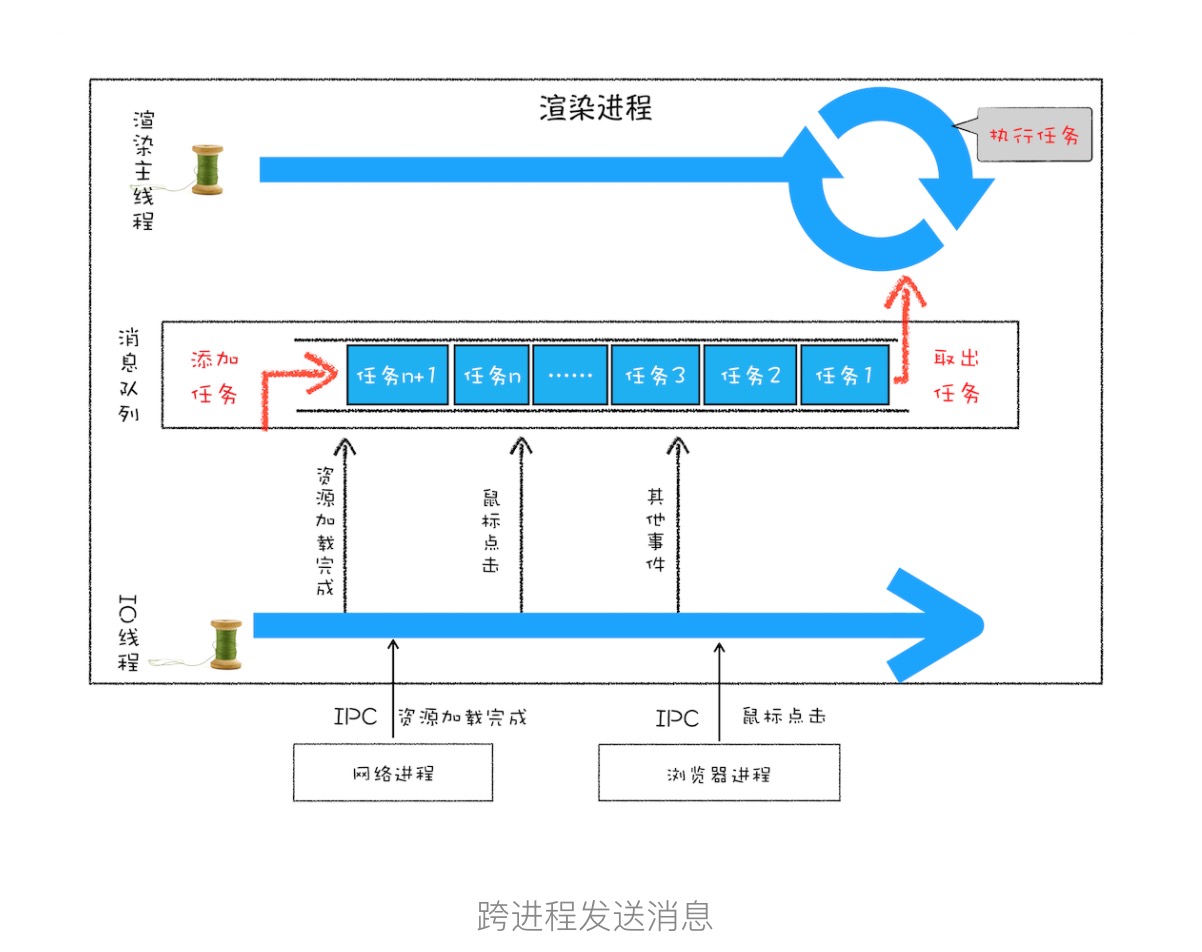
- 2、执行机制:react内部通过模拟requestIdleCallback的实现,自己打造了一个事件机制(参考了浏览器主线程的event loop事件机制,react内部也是通过setTimeout轮询去实现requestIdleCallback,进而实现event loop) 遍历任务执行时,取根结点任务放到任务队列,按照父节点优先,深度优先的规则依次放入节点任务。任务队列是个链表结构,每次放任务时会按任务的优先级排序,原理是比较startTime,(因为除了遍历fiber节点,还会有其他任务放到这个调度器里执行)执行时就按照优先级顺序执行,按照链表遍历顺序,一个个取出子虚拟DOM任务放在消息队列,边取边执行。
需要注意,节点任务在遍历的时候,是不会中断的,当有优先级最高的任务被分过来时,被放到任务队列的队头,shouldYield返回true,当前节点任务执行完后,就去任务队列中获取这个最高优先级任务,执行。
-
workLoopConcurrent类似react的event loop。
-
shouldYield就好比是requestIdleCallback的空闲判断。
-
workInProgress是fiber树上的每一个虚拟节点(node)。
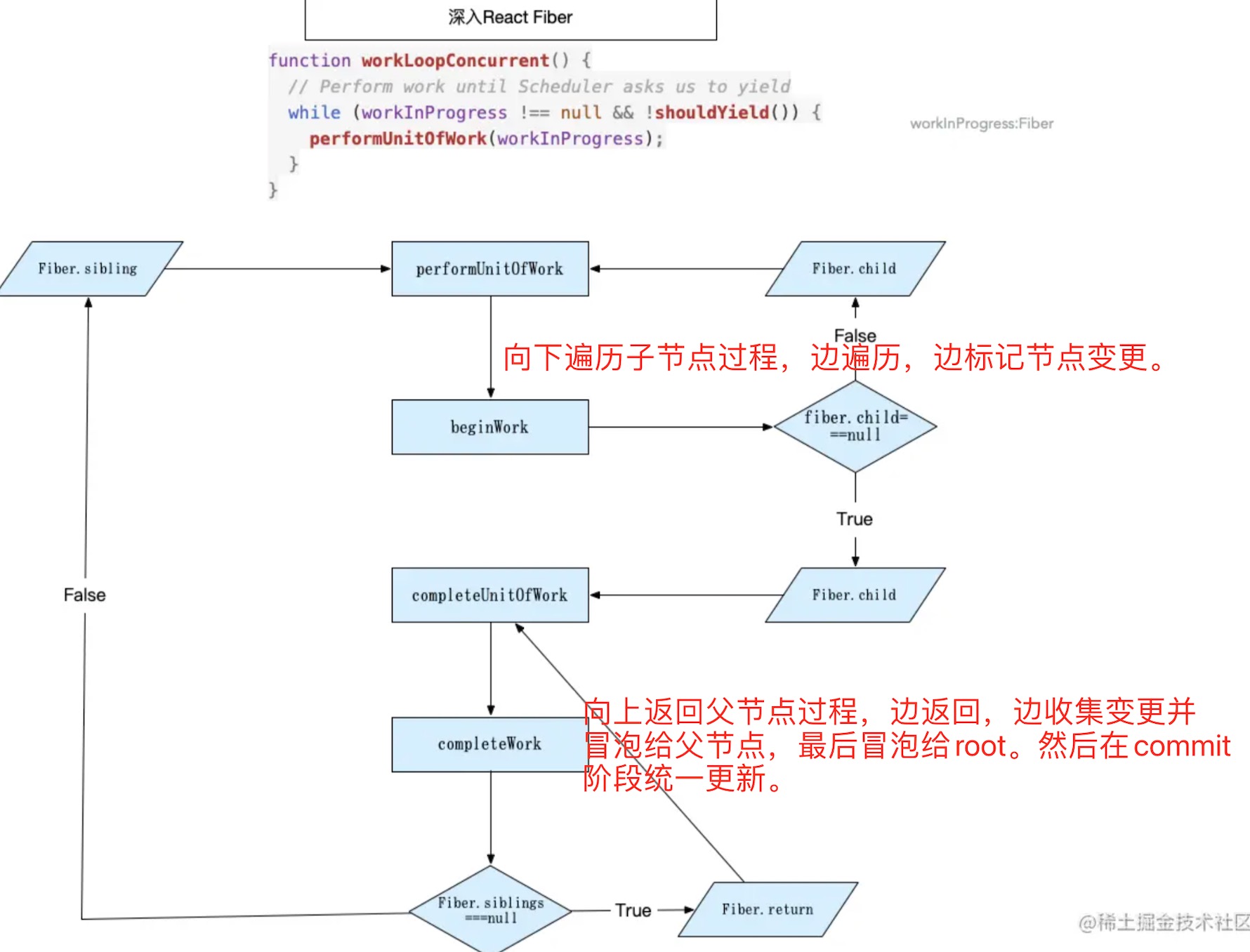
react在performUnitOfWork和completeUnitOfWork两个方法中,处理上述Fiber遍历算法的逻辑,在beginwork和completeWork中完成处理组件的逻辑。 在beginwork中会处理state的更新,此阶段相应生命周期的调用,reconcile的过程(给Fiber节点打上新增,删除,移动等标记(在这里可以看到所有的flags))的过程。在completeWork阶段,会把所有flags的标记,冒泡到一个根结点。以便于在commit阶段更新。
-
3、fiber树的结构(单链表树遍历算法:child、sibling、return)链表以及链表的遍历方式将以上1、2结合在一起,形成一个完整的fiber架构。 因为这样的遍历顺序,中断完还可以接着中断之前的操作继续遍历。 Fiber的每一次渲染,都是从根节点开始遍历。
-
4、requestIdleCallback的图示(下图)
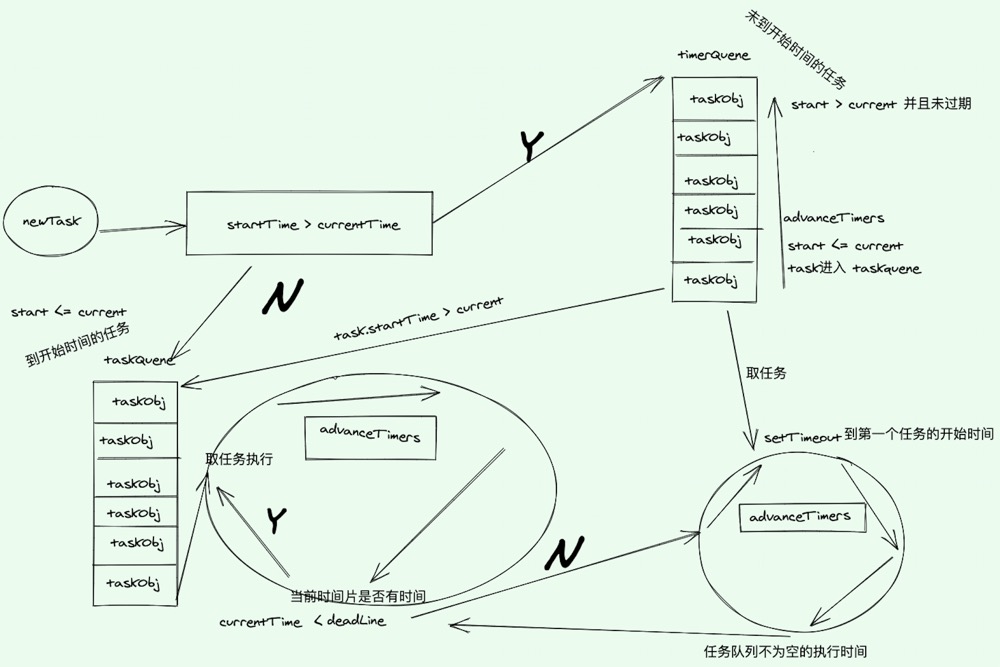
Q&A:fiber的调度器和链表遍历是怎么结合在一起的?
调度器是模拟浏览器线程,链表遍历deism一个个虚拟节点,这些遍历任务会被放在调度器中执行,就像浏览器线程执行渲染/js代码任务一样。
双缓冲也是在链表遍历过程中。它是一个缓存机制,缓存了上一次渲染的fiber tree,以至于不用每次都重新构建一个虚拟树。
参考文章:
2、Hooks
1)useState为什么可以触发render
简单来说就是setState是react暴漏出来的内部方法,会去触发render,使函数组件重新加载。没有做队列的批量更新,因此看起来是同步的。
React 能实现hooks的主要原因是,相较于原来的函数组件,fiber拥有自己的数据结构,也就是FiberNode,可以挂载数据。具体实现是通过renderWithHooks执行的一系列操作。
renderWithHooks函数主要作用: 首先先置空即将调和渲染的workInProgress树的memoizedState和updateQueue,为什么这么做,因为在接下来的函数组件执行过程中,要把新的hooks信息挂载到这两个属性上,然后在组件commit阶段,将workInProgress树替换成current树,替换真实的DOM元素节点。并在current树保存hooks信息。
mountWorkInProgressHook这个函数做的事情很简单,首先每次执行一个hooks函数,都产生一个hook对象,里面保存了当前hook信息,然后将每个hooks以链表形式串联起来,并赋值给workInProgress的memoizedState。
用链表的方式保存,主要是表稳定,确保每个hook的位置,值不会因为位置调换发生变化。
2)为什么不能条件语句中声明hooks
因为一旦在条件语句中声明hooks,在下一次函数组件更新,hooks链表结构,将会被破坏,current树的memoizedState缓存hooks信息,和当前workInProgress不一致,如果涉及到读取state等操作,就会发生异常。
参考文章: 「react进阶」一文吃透react-hooks原理
3、React中setState异步还是同步
判断其更新的代码逻辑如下:
1 | |
setState的执行大致分成两种情况:react内部(生命周期和合成事件)和react外部(原生事件和setTimeout)。
生命周期和合成事件在执行的时候,isBatchingUpdates被置为true,这些setState会批量的被放进一个队列中,在最终finally代码块中被一起执行(performSyncWork)是被批量更新的,所以表现出了异步执行。finally执行后,isBatchingUpdates会被重新置成false,因此原生事件和setTimeout执行的时候,isBatchingUpdates早都被还原成false,因此走的是expirationTime === Sync判断,直接执行performSyncWork方法进行更新。
根据这一特性如何优化setState操作:
1、避免在同一块代码中过对同一个key的state做多次操作。
2、可以在setState接收的回调函数中获取最新的state值。
参考文章: